浅谈 IBM 人工智能工程学(一)

今天是2025年的第一场直播,我们给大家带来一点不一样的东西。在2024年最过火热的话题莫过于人工智能了。但是对很多人来说,人工智能究竟是什么呢?可能你没法一言半语把它说清楚。
今天晚上我们就从非常细微的角度来告诉大家人工智能背后的原理,也就是人工智能工程学。熟悉小熊电脑工坊的朋友应该知道,我们正在进修IBM的人工智能工程学专业证书。这场直播也是分享一下我在学习当中的一些见解和经验,希望能够和大家一起交流。
自我介绍

好,首先做一下自我介绍,我是小熊电脑工坊的主理人,目前我通过了谷歌的提示词入门认证,IBM生成式AI技术的认证,以及范德比尔特大学进阶提示词工程的结业证书。
我在2024年做过很多AI方面相关的尝试,尤其是AI绘画方面,在Midjourney平台也创作过两千多幅的绘画。近期我正在参与IBM的人工智能工程学的专业认证的课程。
什么是人工智能

那么今天晚上就和大家聊一聊在人工智能的背后,它是如何来进行产生的。好,首先回答一个问题,究竟什么是人工智能呢?
我相信大家在很多地方都看过人工智能的内容,包括你每天聊天的ChatGPT、豆包、kimi。那么人工智能究竟是什么?我们如何来给它下一个定义呢?好,大家看这句话,我们把人工智能是当做一种把数据转换成通用能源的技术,怎么理解呢?
在大数据爆发的现在,数据已经成为了一种非常特殊的能源形式。可能他不和你直接进行打交道,但是你却能够用它来做出各种各样的事情,那也就是通用能源的一个概念。好,我们来具体来解释一下。

我们在使用能源之前,首先要经过这么几个途径。就拿我们最熟悉的电能来举例。比如说我们从自然界中获得太阳能、水能和风能,然后通过发电机构把这些能源转换成一个统一的通用能源电力,再把它通过输送线路输送给我们所有的终端设备来使用。手机、电脑、平板、电视、冰箱、空调、洗衣机都可以嫁接在这个通用能源电力上面。
其实对于AI人工智能来讲也是非常类似的。在现在我们把文字、图像、音频视频这种内容产生的数字内容统一称为数据。然后通过人工智能的工程学技术,可以把这些数据转换成一个通用能源,比如说叫它数据集。再把这个数据集输送给人工智能应用,来实现各种各样的功能了。

好,我们来看一下究竟有哪些人工智能应用?比如说你经常遇到的天气预报,想知道未来的天气走势是什么情况。而且你如果想对公司的销售业绩进行一个预测,或者是去把垃圾邮件进行给筛选出来。像目前火热的新能源汽车的自动驾驶,包括我们经常和豆包语音聊天的语音识别。
无论是文字聊天还是图像音频视频的生成,都是最终的人工智能应用。他们都用到了一种通用的能源,就是我们的数据集OK。这样来一讲的话,你是不是对人工智能是什么来产生了一个比较准确的认识呢?好,我们再重复一遍,人工智能是一种把数据转换成通用能源的技术手段。

人工智能工程学方法
好的,那么这个手技术后背后的工程学方法是什么呢?我们为什么要了解这个工程学方法呢?就是它从底层原理理解这个人工智能究竟是在干什么。人工智能并不神秘,它并不是魔法,我们没办法弄清楚它到底是什么。其实它背后都是有一套工程学的方法的,通过非常标准的算法来把我们的数据变成一套通用的能源。

好,我们来看一下目前比较流行的两个大的类型。在人工智能领域,目前存在这么两个大的类型。一种是传统编程,那它是怎么来做的呢?它的做法就是用人来编写固定的程序,来告诉机器在他想要的数据当中存在什么样的规则。每一条规则全部都是由人来写完成。撰写说明的。机器不需要做任何思考,它只需要对照着这些规则去判断是否满足就可可以了。它的一个特点就是传统编程的人工智能非常的精确,而且内容都是预先设定好的,它不太会生成一些额外的内容出来。
好,目前新兴的一种方法,和它相对应的方法叫做机器学习。机器学习就是不依靠编程,而让机器自己去把数据中的规律找出来。就像是人学会一门知识,掌握一门技能一样,由他去观察数据当中的内容,去找出其中的规律。这种方法所产生的结果,它其实是不完全精确的。但是它的作用却非常的庞大。比如说它可以去对新的数据进行预测,或者是对未知的内容进行分类,而且它还能往往生成全新的内容,这就是我们机器学习所带来的一个特点。今天晚上也给大家介绍两种,常见的是机器学习的算法。

好,我们继续往后看。那一般的机器学习的步骤包括哪些内容呢?在IBM的人工智能工程学课程当中,大概是有这么几个步骤组成的。
首先你要去获得行业相关的数据。因为刚刚也说了,人工智能的本质是把数据转换成一种通用能源的一种技术手段。所以你要对数据进行处理之前,首先需要有获得数据的方法和途径。
好在我们获得数据之后,然后接下来该怎么该干什么呢?我们要选择一种合适的算法来对这些数据进行处理,形成模型。那么怎么来选择算法呢?这样有几个趋势可以供你参考,就是去想判断一下你想要的结果到底是做一个什么处理,是对数据进行一个值的预测,还是对数据进行一种类型的分辨呢?如果你选择的算法和你想要的结果不匹配的话,你可能往往得不到一个好的机器学习的模型。所以我们在第二步一定要选择适合你数据类型的算法。
好,当我们确定了一二两步之后,第三步就是安装我们机器学习所依赖的一些工具。这里就是以常见的python语言的一些第三一些工具库来进行介绍。好,接下来我们选择好选获取好的数据,选择好的算法,也有了趁手的工具。接下来我们就要进行模型的训练了,把这些数据经过算法转换成一道模型。但是生成模型之后,并不一定它就是可靠的,我们还要对它进行一些验证。这个的话就有更多的方法来进行了。在这里我们就不做过多的解释,我们来看一个具体的案例是怎么做到的。

好,首先第一个案例,我们来预测一下汽车的二氧化碳的排放量,这个是一个非常典型的行业案例。比如你要比如你作为汽车企业,你想生产一辆汽车,那么你是否要满足国五国六的标准呢?如果我在汽车生产出来之前就想知道这个结论,那应该怎么办呢?这里就可以用到人工智能工程学的方法来进行预测了。
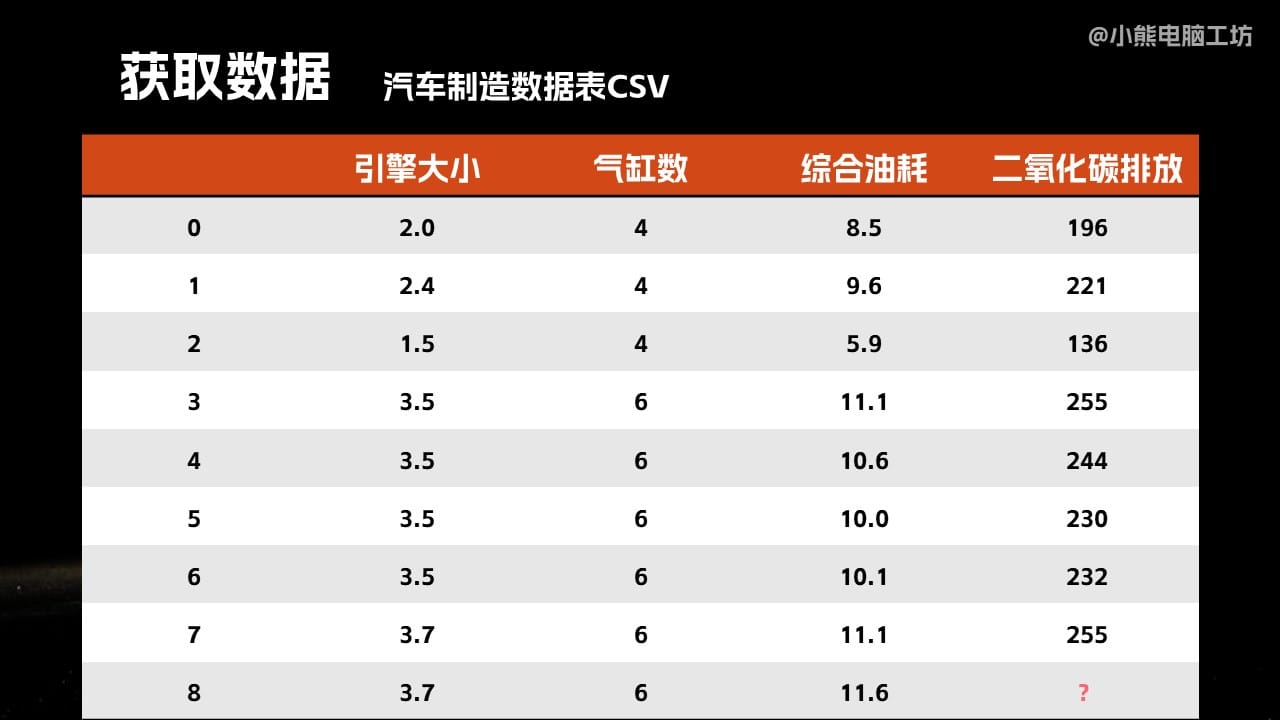
好,我们来再看一下是怎么过,怎么来进行进行这个处理的。首先我们要获得相关的行业数据。在这里我们就拿到了一些汽车制造数据表的CSV文件。它是一些过去的一些厂商所制造汽车的数据。比如说引擎的大小,气缸的数量,这台车的综合油耗表现,以及它的实际的二氧化碳排放量。你可以看到这里有九组数据,0到8,其中0到7都是已知的。那么我们将要造的第八台车,我们想设计它的引擎大小气缸数和综合油耗都知道,但是它的二氧化碳排放达不达标?就可以通过这种方法来进行预测了。
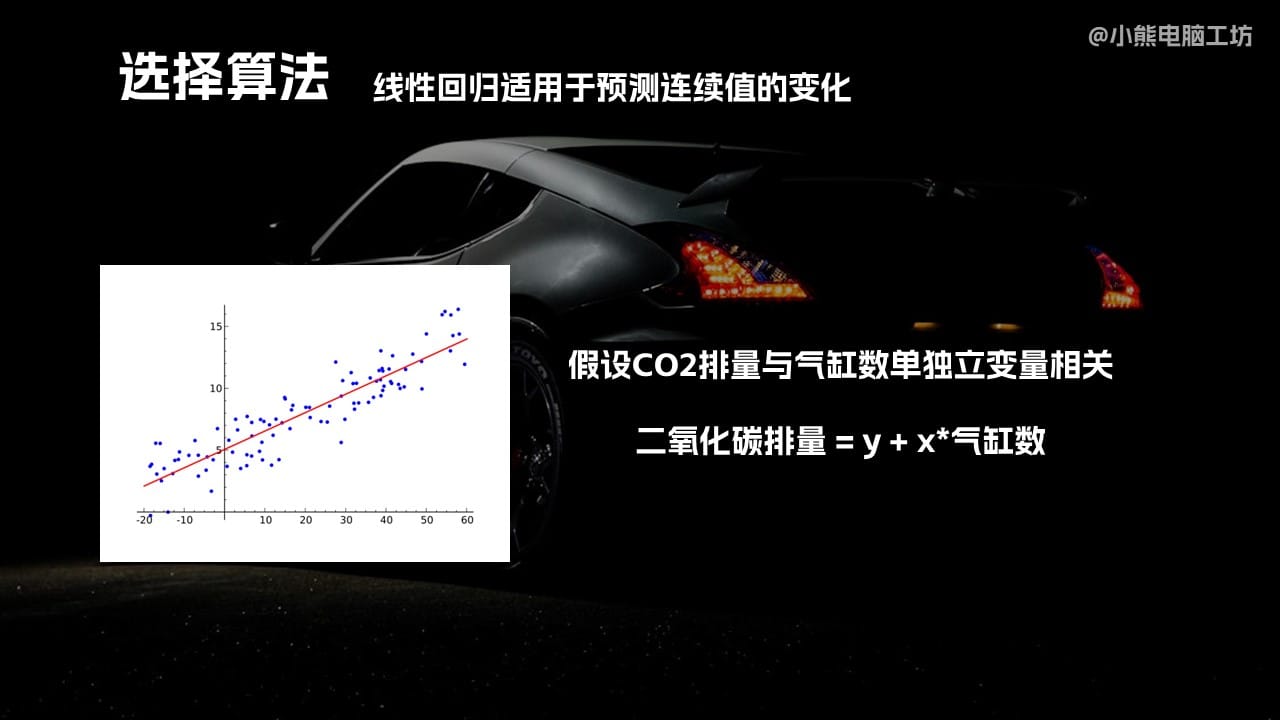
好,我们接着往下看。刚刚知道我们在获取数据之后,要选择一个合适的算法来对它进行处理。在这里我们选择的算法是线性回归。我们可以看看左图,左图的话就是线性回归的一个典型的方式了。假设我们二氧化碳的排放量与一个单独的变量相关,比如说气缸数,那么我们就可以对它进行线性回归的分析,来找到它的一个相关数。线性回归这个方法是用于是预测连续值的变化的,所以针对我们刚刚这个数据是非常有效的。
好,第二步是选择一个合适的算法。刚刚也说了人工智能工程学总共有五步。那么选择算法之后,我们就要来选择合适的工具来进行运算。

我们来看一下到底用了哪些工具,在这个案例里面我们来预测汽车二氧化碳排放需要用到的这么几个工具。第一个是作为基础处理语言的python。第二个是用来读取数据的pandas这个pya库。第二第三个是用来处理这个数据库的派散库叫蓝排。第四个就是用来训练模型的science learn这个排仓库了。我们把这些软件都安装在电脑上之后,就可以对数据进行一些处理。首先用这个pandas把我们刚才所获取到的行业数据读取到表单里面,再用南派对它进行预处理,把它变成一些相关的数据。我们就可以去用c learn来寻找刚才所说的二氧化碳排放量和气缸数之间的相关的工具了。
好,因为篇幅有限,我们不在本次直播当中讨论详细的代码和处理方式。如果你感兴趣,可以点点关注,到我们的社群里面进行沟通交流。我们会免费发布这一次案例所用到的全部的程序源码。

第二个案例,我们来看一下如何预测电信客户的类型。我们知道电信每天会处理很多的客户投诉,那么他究竟是紧急重要还是不紧急?但是重要的这样一种客户类型,你肯定要对他进行一个分类,对不对?好,我们来对看一下这个案例当中的处理方式是什么样的那第一步,我们首先还是要获取这个原始的数据。我们这里提供了一个电信用户数据的SCV表。包括它的居住的地区,它的房子所在的地址,年龄,是否已婚,然后他的收入情况、教育情况、雇主情况、是否退休,他的性别、男女以及他是否拥有固定资产等等。有了这些信息之后,我们再对他的客户类型进行一个预测。

好,我们就可以看到这里的客户类型有1234,总共四个分类。那我们怎么才能知道一个新的客户他究竟是属于哪一个分类呢?我们接下来就要选择一个合适的数据模型来进行预测了。这里我们选择的算法是KAN,就是K个最近邻算法来对数据进行判别。为什么要选择KN这个模型算法模型呢?因为KN是用于判断你当前的数据离它最近的几个点,它的类型是什么?通过这些内容来来推测出你所想要判断数据的类型。所以相比刚才上一个案例中所讲到的线性回归方法,KN这个方法更适合用来预测判断类型这样的一种方法。
OK. 我们知道K是指多少个最近的相邻的单位是吧?假设我们现在K等于3,也就是说从他三个所最近的点来推测出客户的类型。也就是你可以看到左图中的表示,在绿色的圆圈旁边有三个点,分别是两个三角形,一个正方形,那如果通过KAN来进行判断,我们已知有两个三角形和一个正方形,按照它的概率的更大,那么我们推测这个绿色的其实应该是属于三角形这个分类。这是K等于三的情况。
那如果K等于五呢?K等于5,我们可以看到左图上的虚线所标出来的内容,在这个五个点的范围当中,好,就有三个蓝色的正方形和两个红色的三角形。这个时候KN所判别的绿色的圆就属于蓝色的正方形了。
好,大家有没有看出来,实际上一个模型并不是只有一次训练就可以达到理想的效果的,所以我们要对它进行多次的训练才能够找到最佳的这个值。好,我们来看一下这个数据处理所依赖的工具,还是我们的老朋友拍桑这个编程语言。用它的依赖的数据库来进行处理数据。比如说用pandas来进行读取,用long time来进行数据的处理,最后用psych learn这个工具进行模型的训练。好,大家都如果你不清楚这个工具如何使用,也可以点点关注,到我们的社群里面,我们会公布整个项目的源码给大家进行交流。
好,今天的直播内容我们介绍了人工智能到底是什么,以及它的两种常见的算法。我们再来重复一遍,人工智能它其实就是一种把数据变成一种通用能源的科学方法。刚才介绍两种算法,一种是叫做线性回归,它用于预测一个连续值的变化。第二个方法叫做KNN也就是K一个最近0,它用于预测这个分类。

文末福利
好,那么今天的直播正片内容就结束了。在这里我们给大给我们的小熊电脑工坊打个广告。我们目前正上线了一批OAI的提示词课程,这个课程致力于让你学会讲AI的语言,能够让AI为你听话照做。你可以在直播间里点点购物袋,19.9块就可以收入囊中。

那么这个课程到底会讲什么呢?比如我们会教你如何与GPT策划一盏一个线下活动,通过他的任务背景方法来得到一个非常好用的活动的一个方案,是不是非常厉害。不仅如此,我们还会给你提供了更多的学习内容,包括一套创作工具,帮你找到最舒服的一个归因人搭子交给你谷歌最流行的TCREI方法论。而且如果你不会巴格达语法,我们也会手把手的有教程。你现在直接通过聊天对话的方式,就可以学会这一套AI提示词工程,而且你可以随时随地随性的来使用它。最后你还可以通过AI自助和我们的社群互助来提高自己的技术了。
好,今天第一期的浅谈IBM人工智能工程学的直播就到此结束了。感谢大家的观看。如果你对我们的直播内容感兴趣,可以点点关注,也欢迎到我们的社群来进行交流。今天就到此结束了,拜拜。2025年第一场直播到此结束,拜拜。